在上一篇我們了解,只要東西能轉成特徵向量,那不論用歐幾里德距離或餘弦相似度,都可以找出兩個東西間「有多像」!
今天來討論怎麼樣把電影資訊向量化。
但電影的資訊又不是表格,電影資訊要怎麼轉成特徵向量呢?
觀察我從 Yahoo 電影抓來的些資料,有這幾個欄位:名稱、故事情節、卡司陣容、導演、分類(如:驚悚、劇情),我也只能夠用這些資料來判斷哪些電影是相似的或者不是。
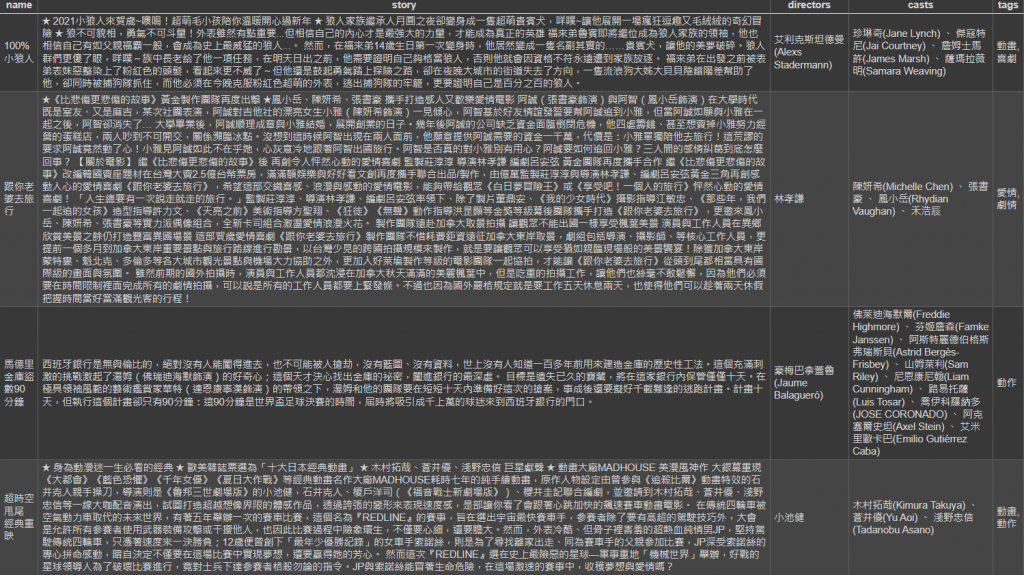
不知道你們有沒有發現這些其實都是文字啊!
既然都是文字的話,用我們能不能用找出文章之間的相似性來找電影的相似性呢?
如果我把名稱、故事情節、卡司、導演、分類,一股腦接在一起,成一篇文章。電影的相似性問題,就會變成是電影相關的文字集結成的文章的相似性問題。

如果我們可以找到代表這篇文章的特徵的話,那若兩文章特徵相近,就代表兩文章是相似。
在日本每一年都會請大家票選最能夠代表了一年的字是什麼字,例如,2021年是金,因為拿了很多奧運金牌;2020年是,因為COVID-19在日本及全球範圍內傳播,讓很多人意識到「密」字(「避三『密』」,即避免密閉、密集、密切接觸)。2019年是「令」因為是令和元年。
我們可以學他們,用關鍵字群來代表一篇文章。若把每一篇文章用幾個關鍵字來代表,以後別人只要看到這一組關鍵字,就能夠知道說噢原來就是這篇文章啊。
例如,講到孫悟空、龜派氣功、天下第一武道會,這些關鍵字,這時候就會想到「七龍珠」。但是如果講到孫悟空、唐僧、金箍棒、蜘蛛精,這時就變成「西遊記」。
這裡會產生一個問題,什麼叫做關鍵字?要怎麼找?
關鍵字的選擇就有一個重點是,因為他要很能代表這篇文章,所以這個關鍵字的選取,就變得格外重要。
能代表一篇文章的關鍵字不會在太多文章裡面出現。也就是說如果我們給100篇文章,只有 3 篇文章會出現這個詞,他就很可能代表這篇文章,成為這篇文章的關鍵字了。
我們需要把電影資訊轉換成為維度統一的向量的方法。為什麼我們要把向量都做成同樣的維度呢?因為能代表文章的特徵向量是相同維度的話,他們才能夠比較,也才能用歐幾里得距離比長短,用餘弦相似度比大小。
如何把文章的關鍵字群轉成同維度的向量呢?
這時候我們就可以引入一個方式叫做 tf-idf 的指標。這個手法可以把文章裡的關鍵字的重要程度找出來。
它的這想法是這樣的,若給他100篇文章,他會把所有的字詞全部都掃描一遍,然後賦予的每一個字詞一個關鍵字的比重,之後我們就可以利用這個關鍵字的比重產生出來的向量,來代表這篇文章了。
這是一個非常經典的方式,但是簡單有用。那 tf-idf 要怎麼使用呢?這我們就明天再和大家解釋囉!


 iThome鐵人賽
iThome鐵人賽